👍👍此篇针对RAG产品经理面试者,附有答案拆解
🌟先思考几个问题
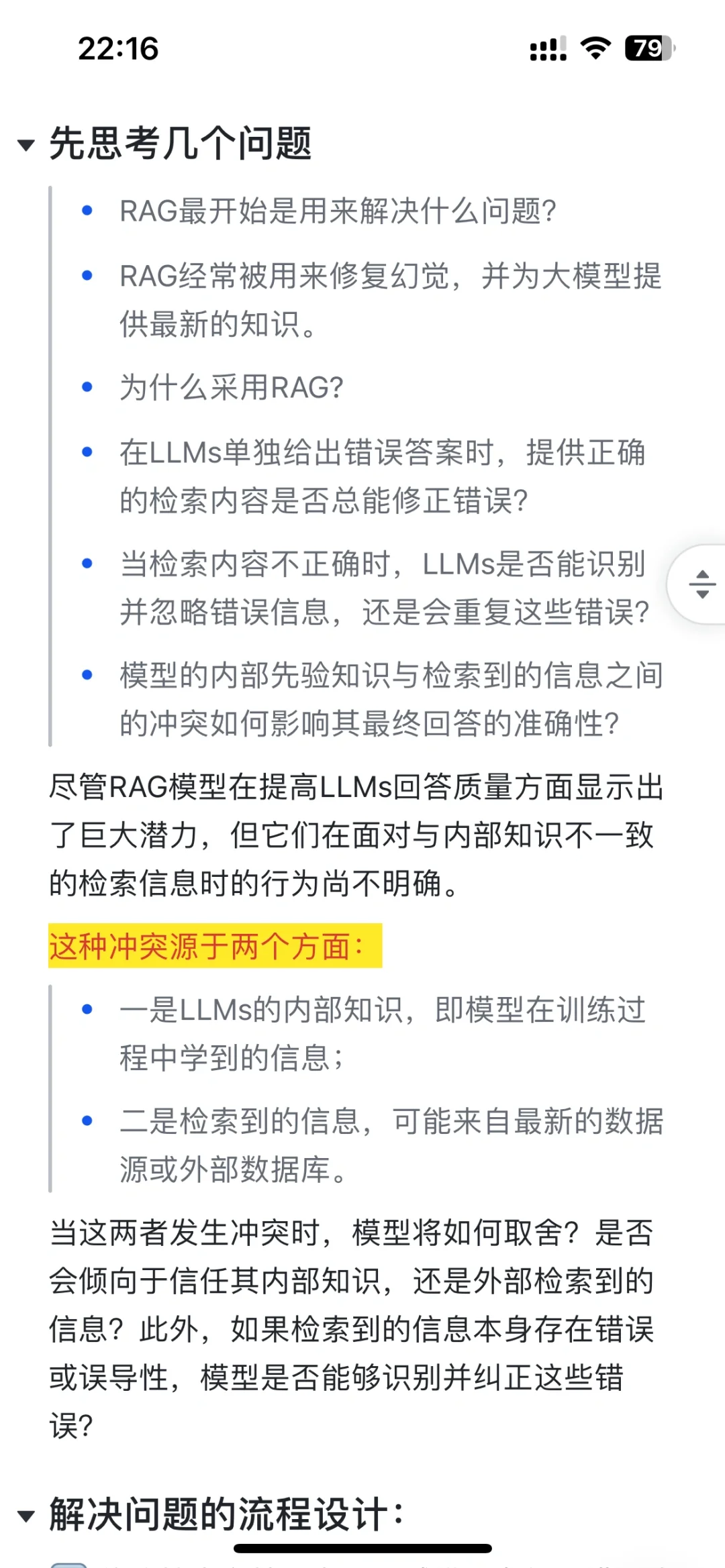
[一R]RAG最开始是用来解决什么问题?
[二R]RAG经常被用来修复幻觉,并为大模型提供最新的知识。
[三R]为什么采用RAG?
[四R]在LLMs单独给出错误答案时,提供正确的检索内容是否总能修正错误?
[五R]当检索内容不正确时,LLMs是否能识别并忽略错误信息,还是会重复这些错误?
[五R]模型的内部先验知识与检索到的信息之间的冲突如何影响其最终回答的准确性?
[六R]尽管RAG模型在提高LLMs回答质量方面显示出了巨大潜力,但它们在面对与内部知识不一致的检索信息时的行为尚不明确。
👍这种冲突源于两个方面:
✅一是LLMs的内部知识,即模型在训练过程中学到的信息;
✅二是检索到的信息,可能来自最新的数据源或外部数据库。
✅解决问题的流程设计:
1️⃣ 修改检索文档:为了测试模型在处理错误或修改过的信息时的表现,研究人员对检索到的文档进行了系统性的修改。
2️⃣ RAG与模型先验分析:
无上下文查询:首先,模型被查询一个问题,但不提供任何上下文,这样得到的答案反映了模型的内部先验知识。
有上下文查询:然后,同一问题再次提出,这次包含了修改过的检索内容。模型的答案被用来评估它是倾向于依赖其内部先验知识,还是倾向于接受检索到的信息。
🌟实验步骤如下:
1.数据集准备:从六个不同领域收集信息,生成问题和答案对。
2.问题生成:使用LLMs根据收集的信息生成问题。
3.答案验证:通过额外的质量控制步骤,确保问题和答案符合特定的格式和标准。
4.扰动生成:对参考文档进行系统性扰动,创建不同的错误版本。
5.模型查询:首先在没有上下文的情况下查询LLMs,记录先验回答和概率。
6.RAG查询:在包含检索内容的情况下再次查询LLMs,比较回答与先验回答的差异。
7.偏好率计算:计算模型对RAG信息的偏好率,并与先验概率和偏离程度进行比较。
🌟关键结论
1. RAG系统的重要性与局限性
2. 内部先验与RAG之间的张力
3. 提示技术的影响
4. 模型间的差异