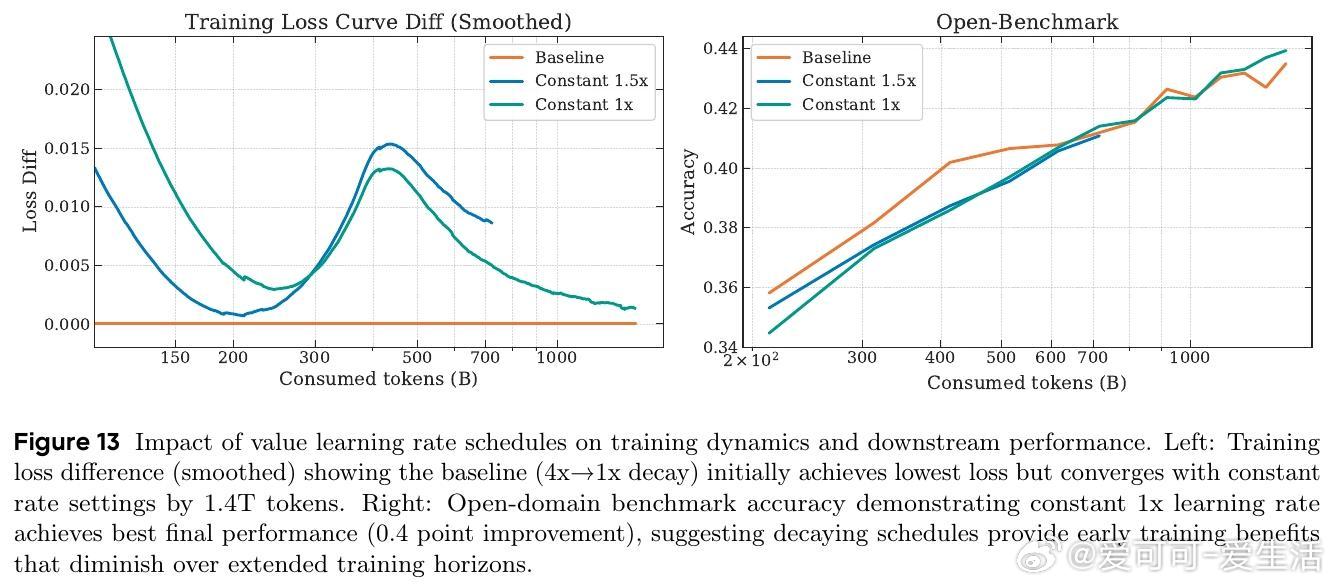
[LG]《UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning》Z Huang, Y Bao, Q Min, S Chen... [ByteDance Seed] (2025)
UltraMemV2:首个在1200亿参数规模下实现与8专家MoE性能持平的记忆层架构,显著提升长上下文学习能力。
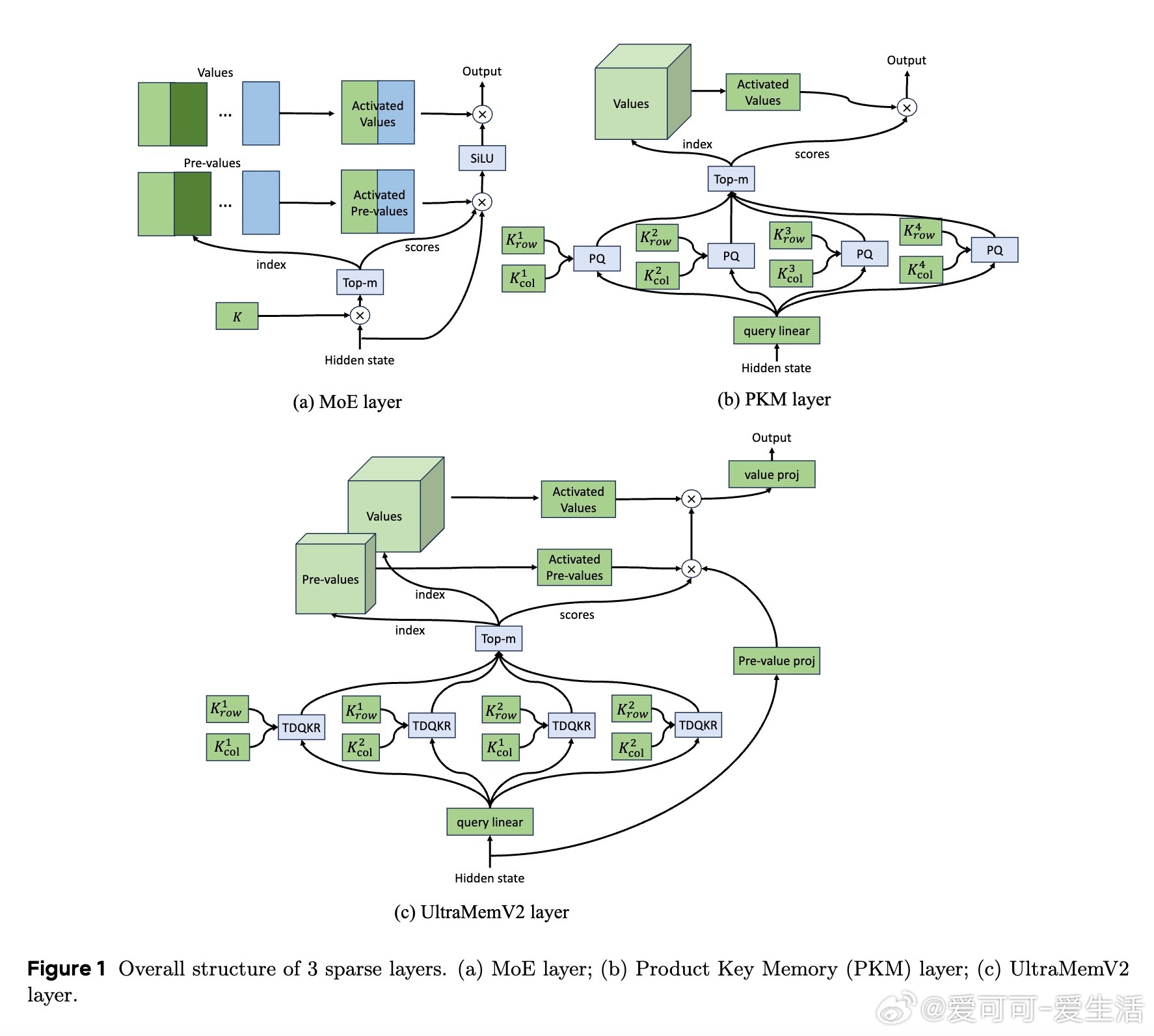
• 架构创新:每个Transformer块内集成UltraMemV2记忆层,强化模型容量扩展与特征融合。
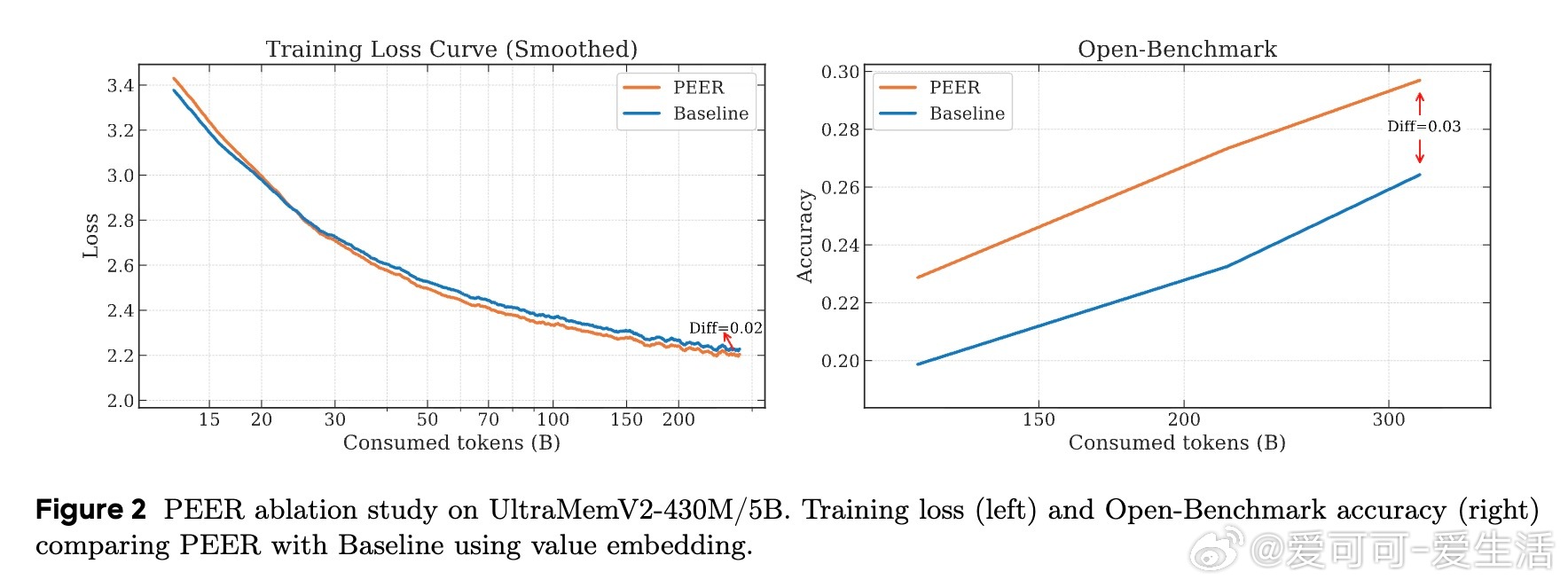
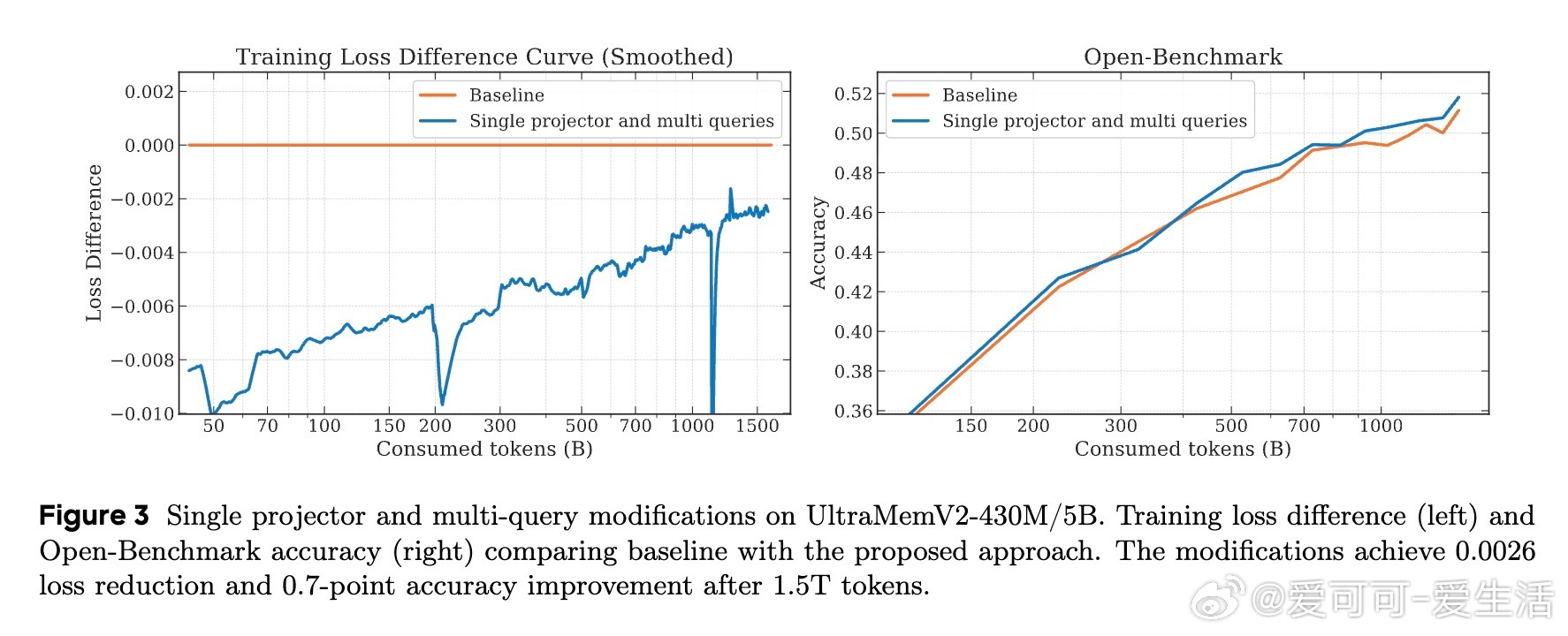
• 简化设计:精简隐式值扩展(IVE)为单线性投影,提升计算效率,采用PEER提出的单内维FFN替代传统值嵌入。
• 参数初始化优化:理论指导下设计初始化标准差,防止训练发散,确保训练稳定性与性能。
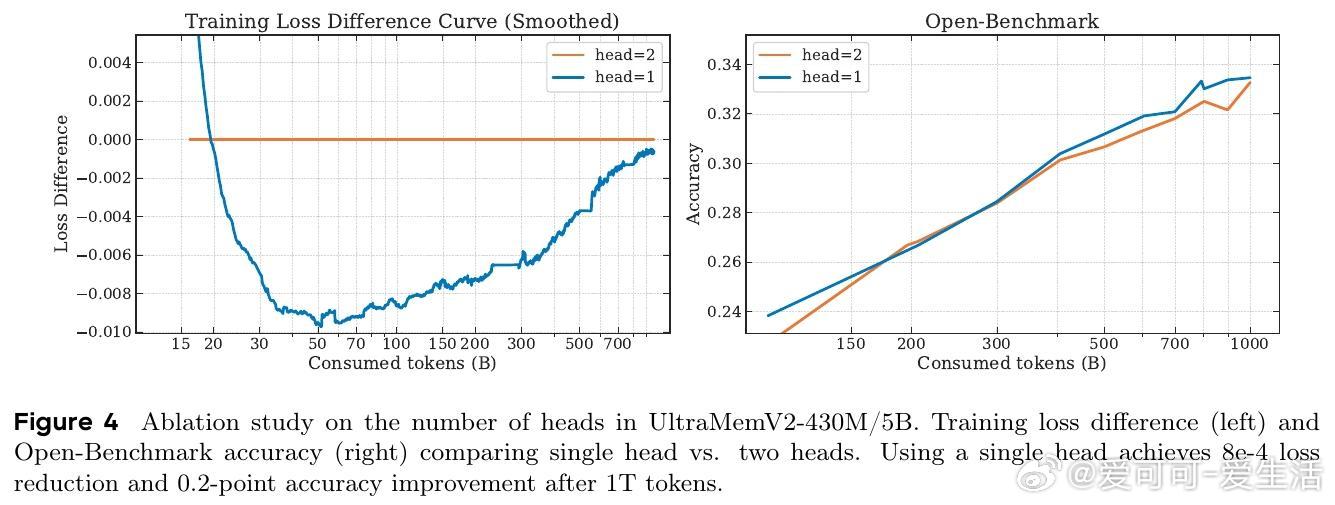
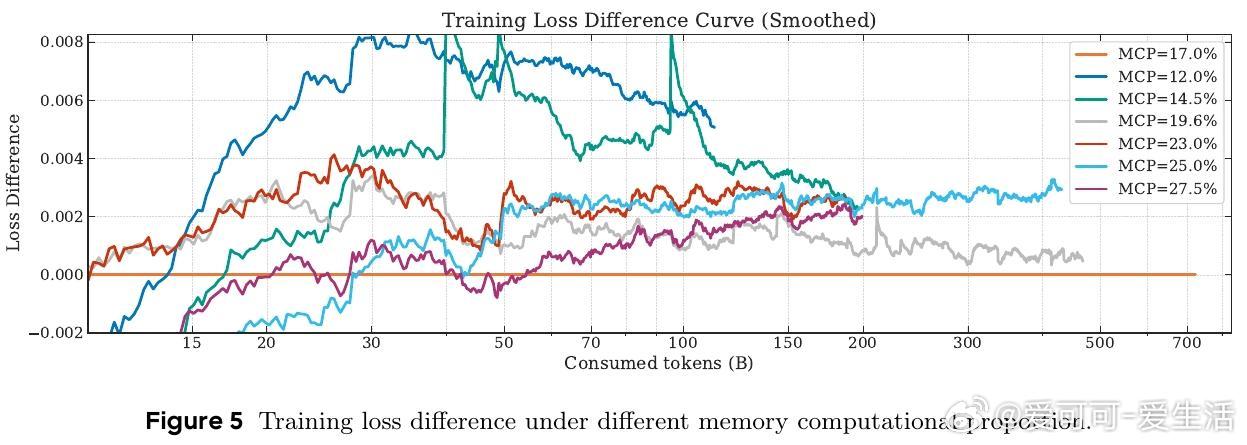
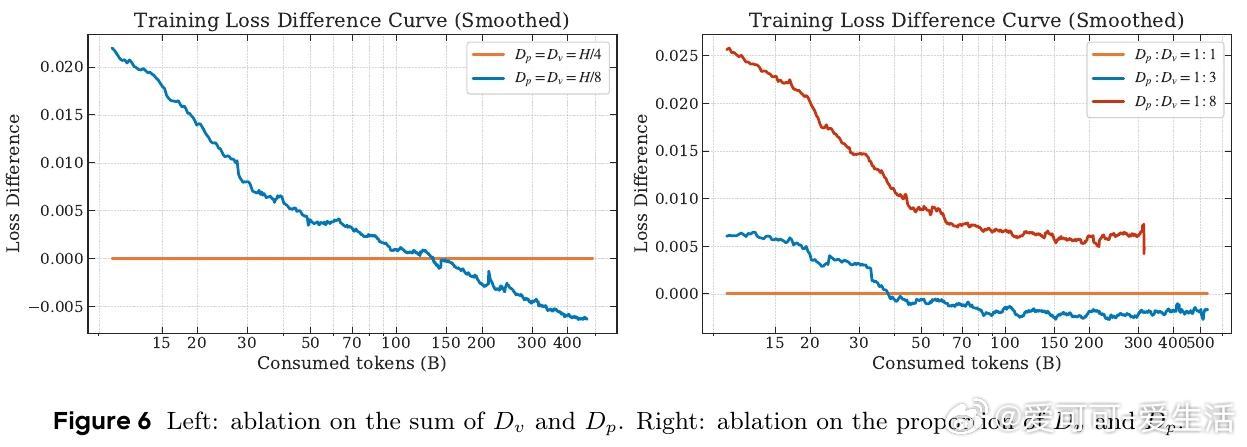
• 计算比例平衡:调整记忆层与FFN的计算资源分配,达到性能与效率的最佳折中。
• 规模验证:成功扩展至激活参数25亿、总参数1200亿,证明激活密度远比稀疏参数总量更关键。
• 性能优势:对比8专家MoE,UltraMemV2在长上下文记忆(+1.6分)、多轮记忆(+6.2分)及上下文学习(+7.9分)任务中表现更优。
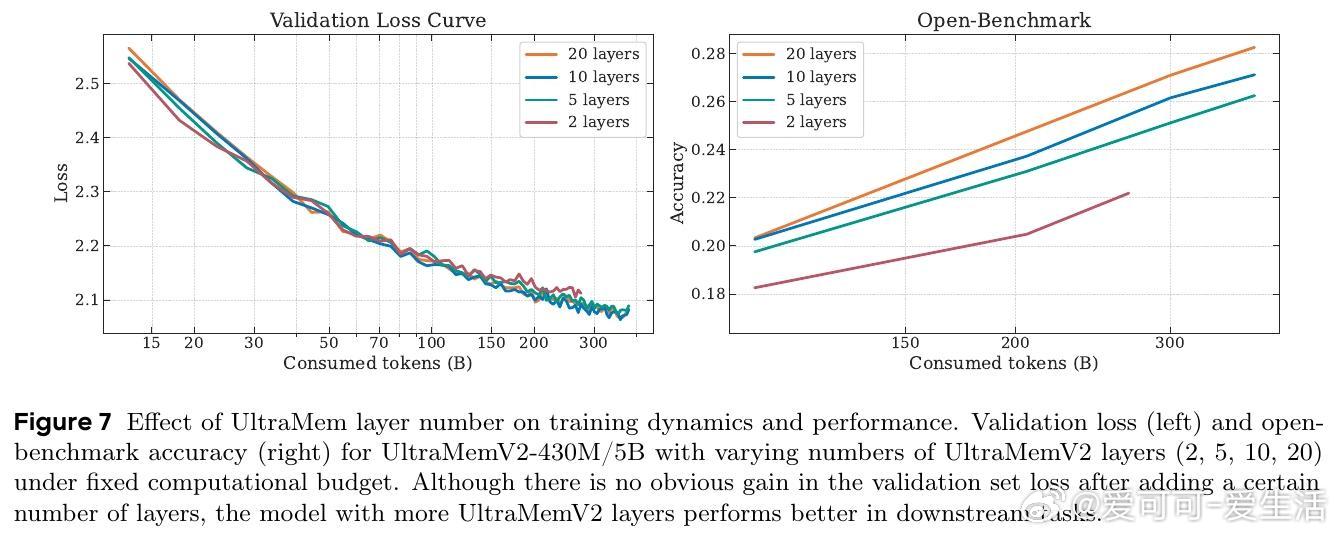
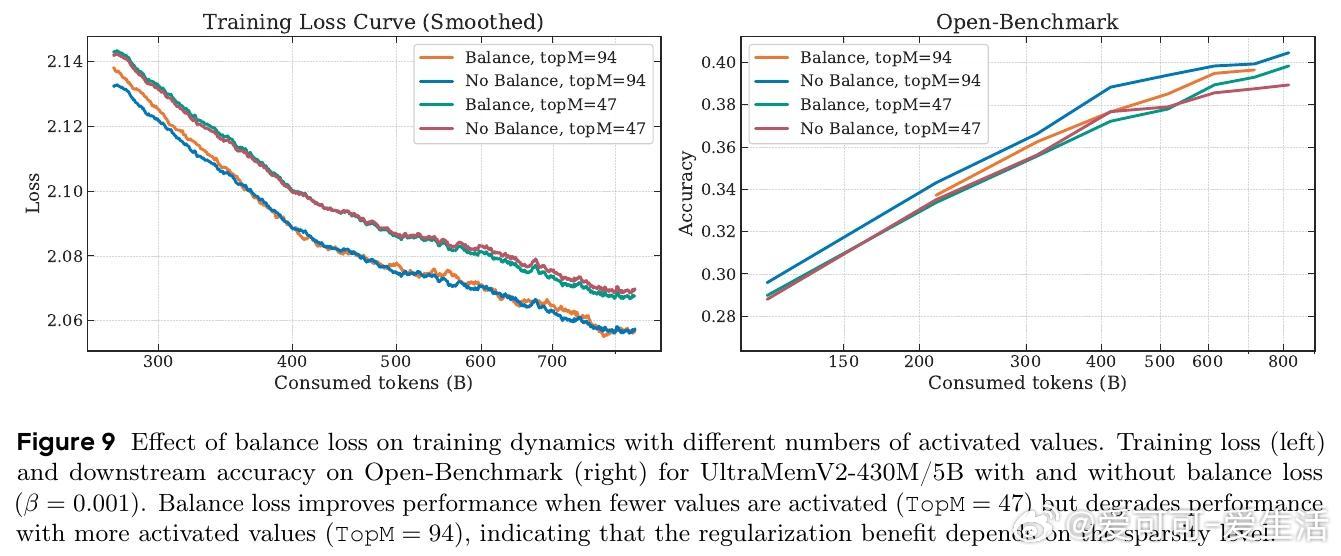
• 训练特性:训练初期表现较弱,需依赖高质量大规模数据及全模型块记忆层支持以达最佳性能。
• 开源支持:[github.com/ZihaoHuang-notabot/Ultra-Sparse-Memory-Network](github.com/ZihaoHuang-notabot/Ultra-Sparse-Memory-Network)
心得:
1. 激活更多参数的“密度”优于单纯增加参数规模,指导未来稀疏模型设计更注重激活策略。
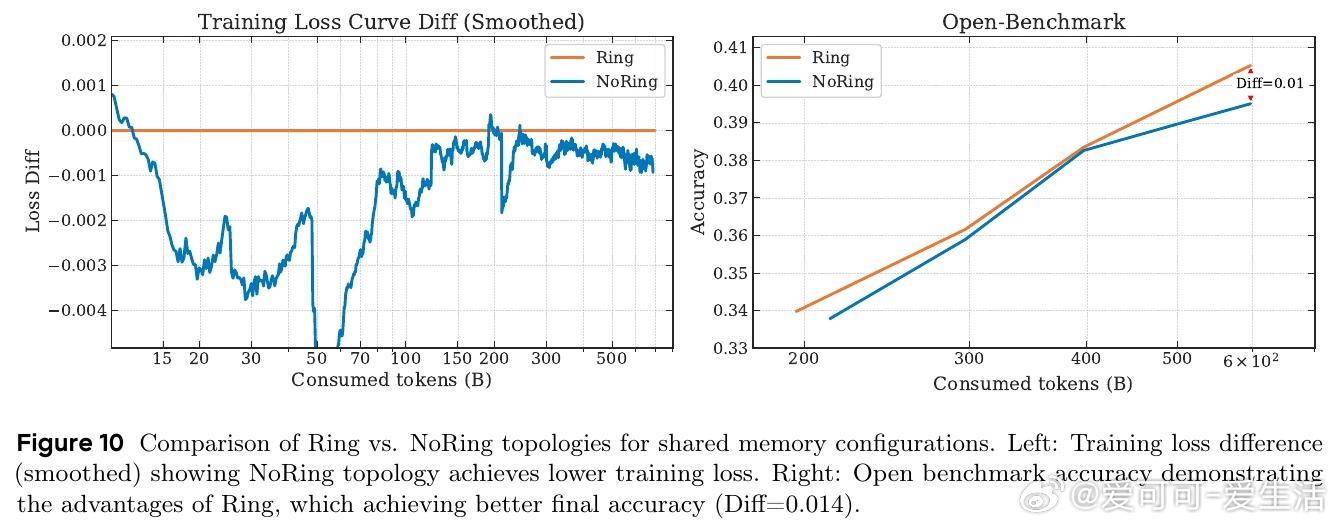
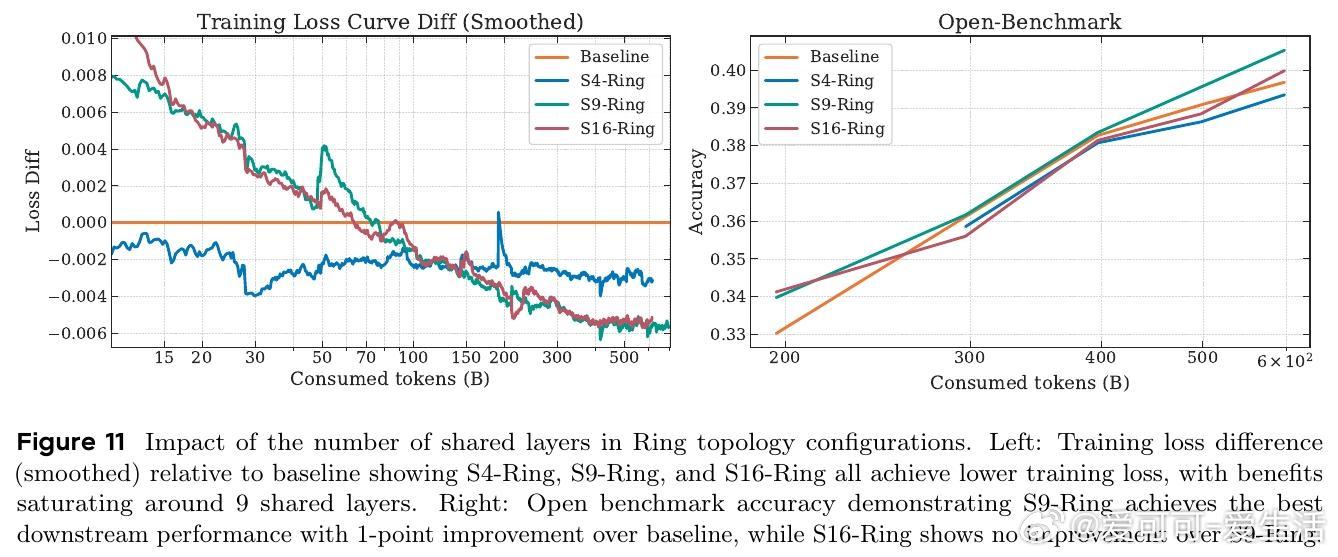
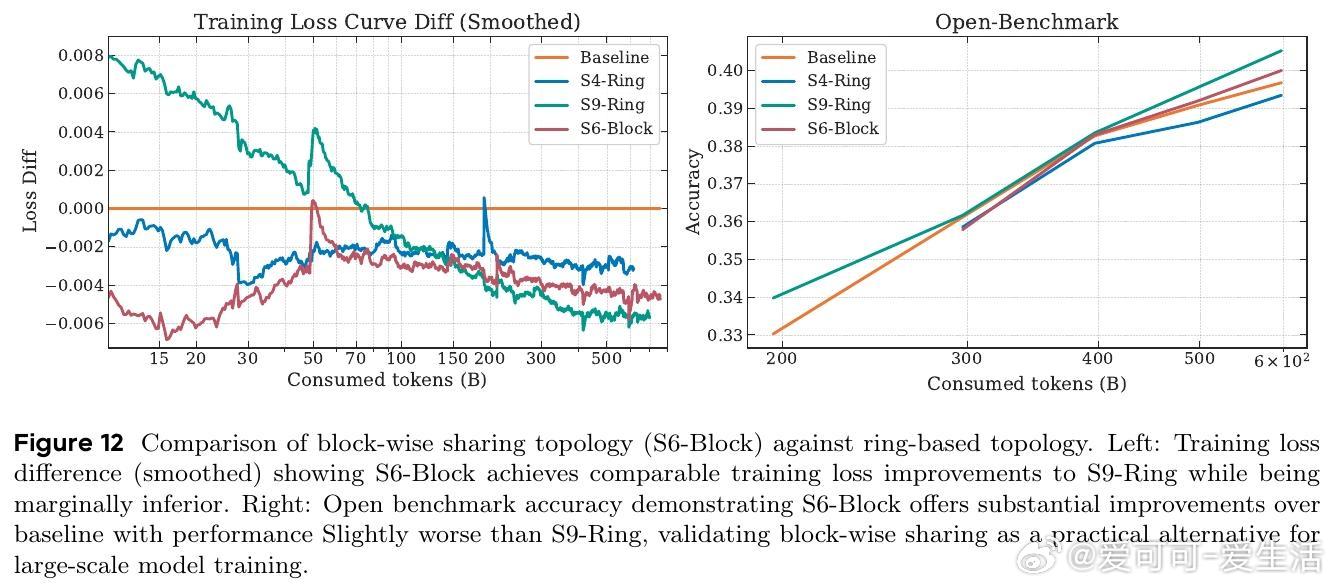
2. 记忆层架构通过减少内存访问,缓解了MoE模型推理时的瓶颈,提升大型稀疏模型部署效率。
3. 训练稳定性关键依赖于合理的参数初始化与计算资源分配,影响模型收敛及最终性能。
详见🔗arxiv.org/abs/2508.18756
人工智能大规模模型稀疏计算长上下文学习神经网络架构记忆网络