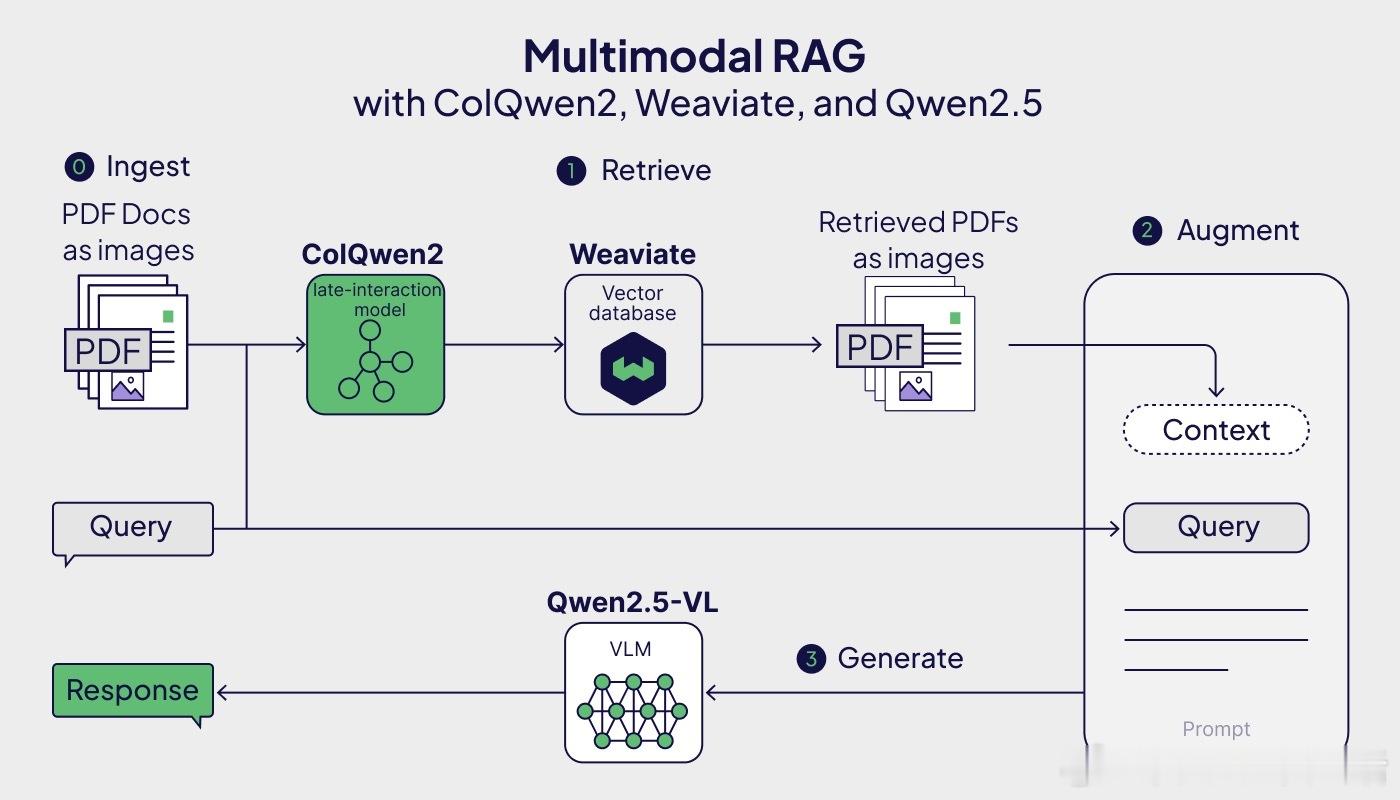
多模态 RAG 技术在 PDF 处理上实现突破,无需 OCR、布局检测或分块,开辟新路径:
• 直接将 PDF 页截图作为图像输入,利用 ColQwen2 多模态后期交互模型精准嵌入
• 利用 weaviate 向量数据库存储,实现高效检索
• 查询时用 ColQwen2 嵌入文本,快速定位相关 PDF 文档
• 最终由视觉语言模型 Qwen2.5-VL 生成准确回答,融合视觉与文本信息
此方案绕开传统 OCR 层,极大简化流程,尤其适合图文混合复杂的 PDF 文档。对比 OCR,截图方法在特定场景(如医疗处方)表现出更灵活的适应性,且具备良好的扩展潜力。
实操意义:
- 免除 OCR 误差和布局解析难题,提升多模态检索的稳定性与效率
- 结合向量数据库与视觉语言模型,实现从图像到文本的无缝连接
- 可针对专业领域(如医疗)微调,提升特定文档类型的理解深度
相关资源与讨论链接🔗:
github.com/helloiamleonie/ColQwen2
多模态AI向量数据库视觉语言模型PDF智能处理自然语言理解