[LG]《Predicting the Order of Upcoming Tokens Improves Language Modeling》Z M. K. Zuhri, E H Fuadi, A F Aji [MBZUAI] (2025)
提升语言模型训练效果的新路径:预测未来Token顺序
• 传统大语言模型(LLM)训练依赖下一Token预测(NTP),虽有效但存在误差积累和学习瓶颈问题。
• 多Token预测(MTP)引入多个预测头尝试预测若干未来Token,提升部分生成任务表现,但难度大,规模敏感,且对标准NLP任务提升有限。
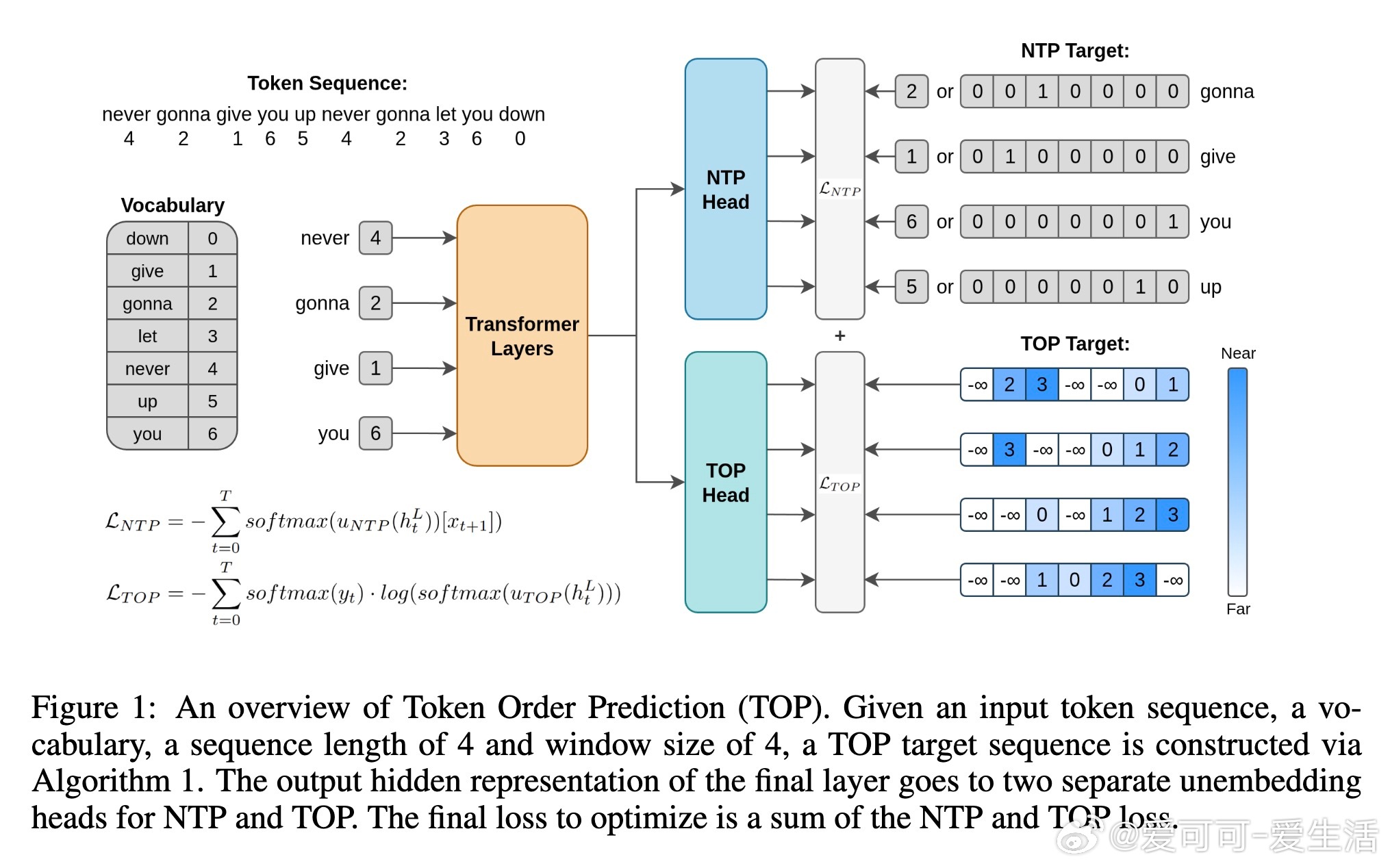
• 本文创新提出Token Order Prediction(TOP),用学习排序损失训练模型预测未来Token的出现顺序,替代精确预测未来Token内容,显著降低任务难度。
• TOP仅需额外一层线性unembedding层,参数开销远小于MTP,且窗口大小灵活调整,计算效率高,训练开销更低。
• 在340M、1.8B、7B参数规模模型上,TOP均优于NTP和MTP,尤其在标准NLP基准测试(Lambada、HellaSwag、TriviaQA等)表现更稳定,且随模型规模扩大表现提升明显。
• TOP训练时虽NTP头的训练损失略高,但在测试上表现反而更优,推测其具有正则化效果,有助于模型泛化。
• 推理时仅使用NTP头,无需额外计算,兼容现有Transformer架构,易于集成与部署。
心得:
1. 未来Token的顺序信息比精确内容预测更易学习,辅助任务设计趋向“软”目标更利于表示学习。
2. 轻量级辅助头设计显著提升训练效率和可扩展性,避免了MTP因多头带来的计算爆炸。
3. 训练目标的合理松弛不仅提升性能,也可能带来更好的模型泛化,值得在其他序列建模任务中探索。
探索TOP,未来语言模型训练可望实现更精准、高效的表现提升。
详情🔗arxiv.org/abs/2508.19228
代码👉github.com/zaydzuhri/token-order-prediction
语言模型深度学习自然语言处理辅助任务模型训练大规模预训练